QckRead
Machine Learning approach for Text Summarization
Advised By Prof. Doug Downey, Final Project for EECS 349 Machine Learning course
Find Out MoreTeam Members

Ashwin Shanmugasundaram
Masters in Computer Science
skantha@u.northwestern.edu

Imran Shaikh
Masters in Computer Science
imranshaikh2013@u.northwestern.edu

Nikhil Amba Madhusudhana
Masters in Computer Science
nikhilam@u.northwestern.edu
Introduction/Motivation
Many a times readers of news articles find most of the news verbose and cumbersome to read at an entire stretch, but still like to get the essence of the news without having to read the entire article. Headlines of the news just provides the user with the subject of article thereby not providing the important details of its causes or effects
QckRead uses machine learning approach to summarize a news article. The approach begins by first classifying the article based on its genre or news category. We then look for similar flow of ideas in sentences with reference to the title to identify important aspects and then sentences are weighed based on its importance and content
Dataset
The datasets used for the purpose of this project are multiple and the data extracted is used to perform specific functions to help provide the end result
20newsgroup
First to begin with for the purpose of genre classification we have utilized the 20newsgroup dataset. This dataset is freely available for academic use. The dataset consists of around 20 thousand articles from various newsgroup classified into 20 categories with a near even distribution of articles across the categories. The dataset was used to perform and test the genre classification aspect of the project.
English Dictionary
The entire English dictionary has been downloaded and complied into structural data so as to enable us to cross reference words identified in the genre classification and the during summarization to ensure we discard conjunctions and proper nouns and to also establish the correctness of words so that the classifier does not contain garbage words occurring due to erroneous parsing of text files, which reduce its efficiency.
English thesaurus
The entire English Thesaurus is downloaded and structured for the purpose of understanding the 'ideas' behind words. The Thesaurus used in this case is roget's english thesaurus. The thesaurus has been divided into buckets of words which portray a similar meaning or idea and each bucket assigned a number. So this is used to reduce the article into a sentence to an array of bucket numbers which is used to compare the similarity of ideas of and meanings of sentences as a whole.
Methodology
1. Text Classification
Naive Bayes Classifier
The algorithm begins by training the genre classifier using the Naïve Bayes technique with the use of the 20newsgroup dataset
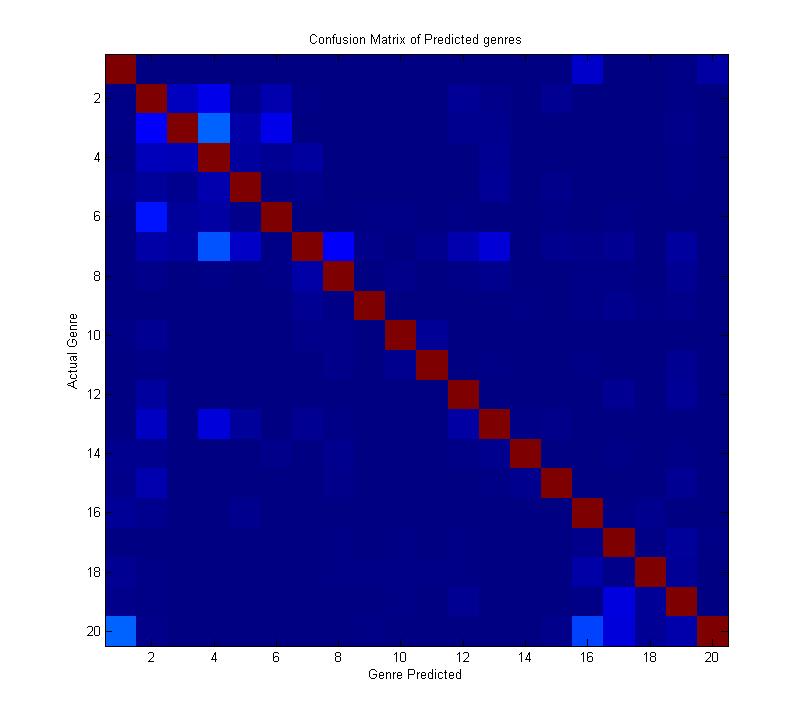
Confusion Matrix
20X20 confusion matrix is built where each row gives the actual genre of the article and each column depicts the genre that the Naive-Bayes predicted, thus the diagonal element gives us the number of rightly predicted genre. This method gave us an accuracy of about 90-93%
Buckets
Data is cross referenced with the dictionary to eliminate conjunctions and proper nouns. The thesaurus is then read in and structured into buckets so as to be readily available when summarizing the article.
2. Text Summarization
-
The article to be summarized is read in and split into independent sentences. Once this is done the sentences are converted into bucket arrays.
-
The title of the article is used in the begining as reference to establish the important aspects of the article. Now we look for a sentence with the longest common subsequence with respect to the title.
-
Now we remove the sentence and insert it into the summary and higher weights are assigned to the words present in the vocabulary. For words not present in the vocabulary are added to the vocabulary with low threshold weights, which are reinforced by summarizing more and more articles This provides for continuous automatic updation of the knowledge base so as to improve the summarization at every successive iteration.
Results
The confusion matrix showing the articles predicted correctly and incorrectly, where the diagonal elements are of highest intensity showing that it predicted the articles correctly the y-labels been the actual genres and the x-label depicting the value that the algorithm predicted.
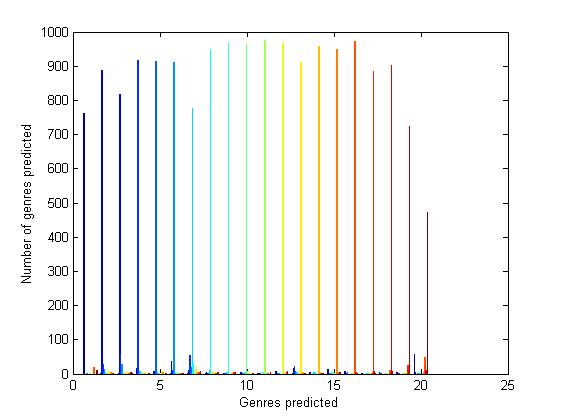
This graph gives for each class the number of articles it has predicted incorrectly and number of articles it has predicted correctly, the bar with the maximum height is the final class predicted.
Click here to download the detailed report
Click here to view the sample summarized articles